Introduction to Libraries of NLP in Python — NLTK vs. spaCy
The two significant libraries used in NLP are NLTK and spaCy. There are substantial differences between them, which are as follows:
- NLTK provides a plethora of algorithms to choose from for a particular problem which is a boon for a researcher but a bane for a developer. Whereas, spaCy keeps the best algorithm for a problem in its toolkit and keep it updated as state of the art improves.
- NLTK supports various languages whereas spaCy have statistical models for 7 languages (English, German, Spanish, French, Portuguese, Italian, and Dutch). It also supports named entities for multi-language.
- NLTK is a string processing library. It takes strings as input and returns strings or lists of strings as output. Whereas, spaCy uses an object-oriented approach. When we parse a text, spaCy returns document object whose words and sentences are objects themselves.
- spaCy has support for word vectors whereas NLTK does not.
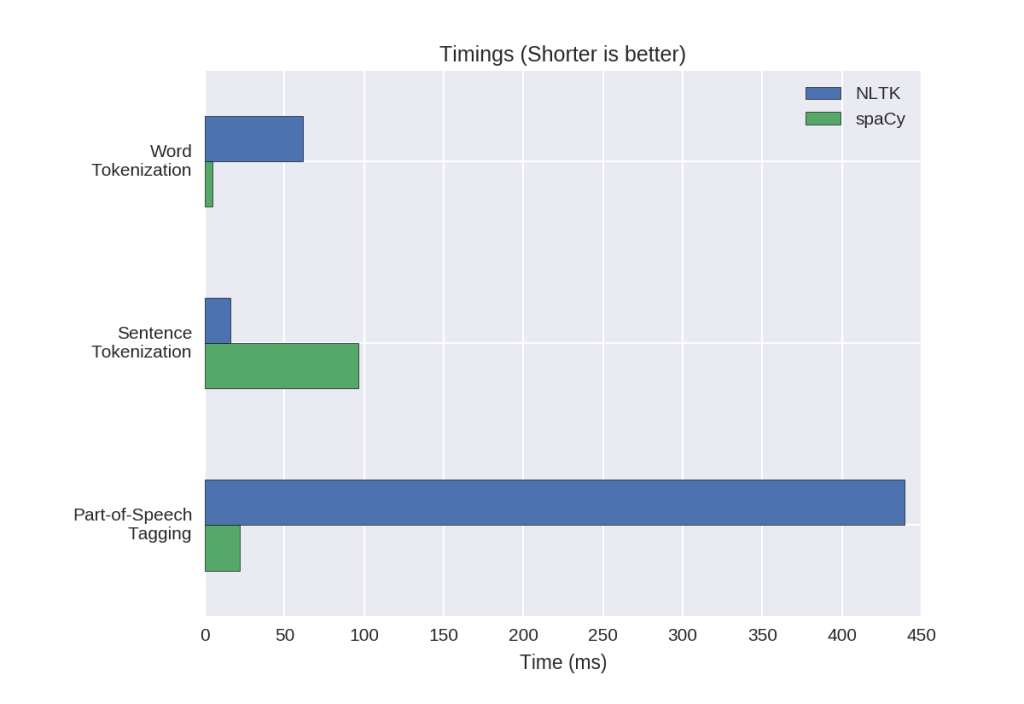
- As spaCy uses the latest and best algorithms, its performance is usually good as compared to NLTK. As we can see below, in word tokenization and POS-tagging spaCy performs better, but in sentence tokenization, NLTK outperforms spaCy. Its poor performance in sentence tokenization is a result of differing approaches: NLTK attempts to split the text into sentences. In contrast, spaCy constructs a syntactic tree for each sentence, a more robust method that yields much more information about the text.
PS. will add info about Gensim soon.



Comments
Post a Comment