Generating Artificial Faces with Machine Learning

In today’s article, we are going to generate realistic looking faces with Machine Learning. In order to do so, we are going to leverage Generative Adversarial Networks (GANs), and more specifically Deep Convolutional Generative Adversarial Networks (DCGANs). By the end of this post, you will be able to successfully train a GAN to sample an infinite amount of images based on a given dataset, which in our case will be human faces.
Let’s start with a simple question.
Can you tell which of the following images are real and which ones are fake?

We will get back to this later, stay tuned!
Meanwhile, let’s proceed with GANs and try to artificially create realistic looking faces.
Deep Convolutional Generative Adversarial Networks (DCGANs)
If you are completely new to the GANs field, I recommend you to check my previous article that covers its absolute basics.
Even if you are not a beginner, I still recommend you to take a look since the face generator is significantly based on the image generator project.
Face Generator
It’s commonly easier to understand difficult concepts while seeing the actual underlying mechanisms, so as usual, I am sharing my project on GitHub so you can see the code
and on Kaggle where you can run it in the cloud.
High-quality dataset is a crucial part of the Machine Learning pipeline. My dataset that I prepared for this project contains selected images from CelebAdataset that were additionaly cropped to only faces. Feel free to check it out and use it in your applications.
As I said before, face generator is significantly based on my previous image generator project and they both use the same network design by Radford et al., 2015 that can be seen below.
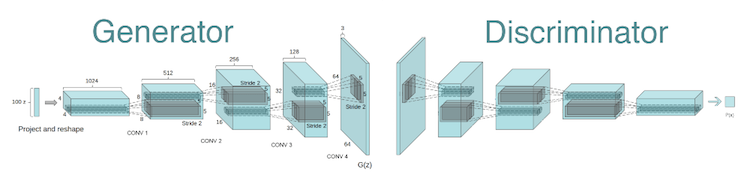
Despite considerable similarities between the two projects, I am going to show you, how you can significantly alter network behavior with seemingly small tweaks.
Before we proceed to the tuning/training part, let’s start with defining our goal.
Our primary goal is to create artificial samples of human faces.
We could consider it as our high-level ‘business’ goal and while it correctly describes what we are trying to achieve, it’s very unspecific and rather vague then mathematically precise.
Are we able to come up with something more specific?
Yes!
Our training process consists of the “battle” between the discriminator and generator. They both strive to reduce their losses. If they are well-balanced they will both tend towards some convergence points. But for what convergence points should we strive given the following loss functions?
def model_loss(input_real, input_z, output_channel_dim):
g_model = generator(input_z, output_channel_dim, True)
noisy_input_real = input_real + tf.random_normal(shape=tf.shape(input_real),
mean=0.0,
stddev=random.uniform(0.0, 0.1),
dtype=tf.float32)
d_model_real, d_logits_real = discriminator(noisy_input_real, reuse=False)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True)
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_model_real)*random.uniform(0.9, 1.0)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_model_fake)))
d_loss = tf.reduce_mean(0.5 * (d_loss_real + d_loss_fake))
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_model_fake)))
return d_loss, g_loss
Our perfect final state would look like this:
- Generated samples look good and reflect the input dataset.
- Discriminator converges to 0.5 - 50% accuracy, discriminator does not know how to distinguish between real inputs and fake ones.
- Generator converges to 1.0 - 100% accuracy, all of its samples are so good that discriminator considers them as reals.
Now as we know what to look for in our training process, let’s begin tuning our network.
Training
Knowing what to look for, I came up with the following hyperparameters.
DATASET_SIZE = 100000 IMAGE_SIZE = 128 NOISE_SIZE = 100 LR_D = 0.00004 LR_G = 0.0002 BATCH_SIZE = 64 EPOCHS = 60 BETA1 = 0.5 WEIGHT_INIT_STDDEV = 0.02 EPSILON = 0.00005
Let’s take a look at the visualization of the training process.

Final losses after 60 epochs of training look as follows.
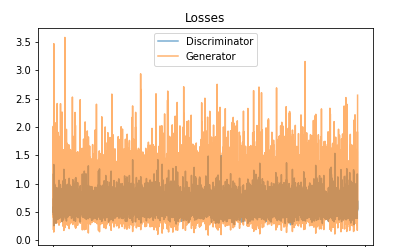
They aren’t perfect but we can see that D loss tends towards 0.5, G loss to 1.0 (on average) and we are generating better samples with every consecutive epoch - very good indicators!
FYI: Whole training process of 60 epochs took about 100h hours on Tesla K80 GPU (Kaggle).
Results
Here are the results, high-fidelity artificially generated faces.

While some of them look malformed and fake, most of them look very real!
We can see that our face generator isn’t perfect and has problems with for example glasses, but in overall, its performance is very satisfactory given the very limited resources.
What’s Next?
With the Face Generator project we’ve showed that it’s definitely possible to generate lifelike looking faces with generative adversarial networks. It was viable even with the very limited resources like in my case, so we can draw a conclusion that it would be possible to render better and higher resolution samples in bigger and more advanced research labs.
With that being said, we are entering a new era in which we should be more cautious in what we trust as creating high-fidelity fake content is now easier than ever.
One more thing.
Do you remember these images from the beginning of the article?
In case you still wonder if they really exist.
They don’t. They are all generated by the state-of-the-art StyleGAN. Check the link below to learn more.
gsurma/face_generator
github.com
Questions? Comments? Feel free to leave your feedback in the comments section or contact me directly at https://gsurma.github.io.
Thanks:


Comments
Post a Comment